Pre-trained acoustic models learned in an unsupervised fashion have exploded in the domain of speech. The representations discovered by CPC, wav2vec 2.0, HuBERT, WavLM, and others, can be used to massively reduce the amount of labelled data to train speech recognizers; they also produce excellent speech resynthesis.
However, while pre-trained acoustic representations seem to be nicely isomorphic with phones or phone states under optimal listening conditions (see, for example, here, here), very little work has addressed invariances. Do the representations remain consistent across instances of the same phoneme in different phonetic contexts (i.e., are they phonemic or merely allophone representations)? Do they hold up under noise and distortions? Are they invariant to different talkers and/or accents?
The limited research that has addressed these questions directly suggests:
- that state-of-the-art models have some degree of robustness to talker change
- that they are fragile when surrounding phonetic context changes
- and that they are highly sensitive to noise and distortions, including time-dilation However, this research remains extremely limited: evaluation is limited to a few models, and the two standard benchmarks (ZeroSpeech: intrinsic representation quality; SUPERB, SUPERB-SG: downstream tasks) only assess talker invariance, and only in a superficial way. There is no standard evaluation for invariance to context, noise, and other distortions, and only limited evaluation of talker-/accent-invariance.
For example, the analysis of Hallap et al (now available publicly via Task 1 of the Zero Resource Speech Benchmark: see below) examined in detail whether systems learned context-dependent allophone representations or something more like context-independent phoneme representations.
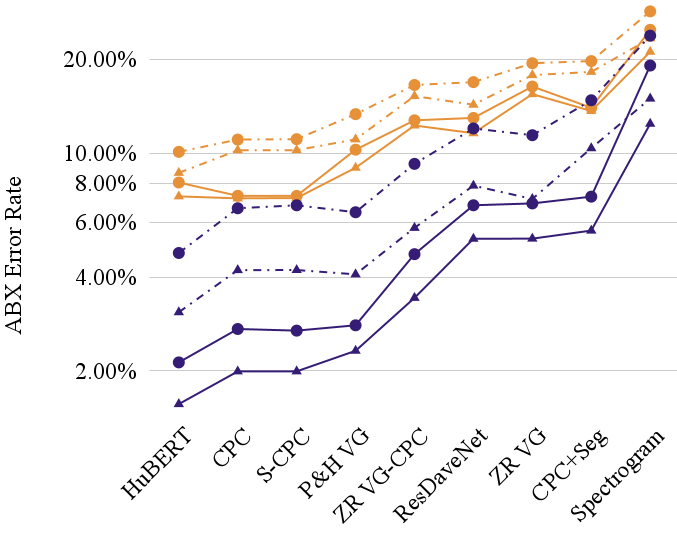
The results, shown above for a handful of recent systems, demonstrate that phoneme ABX discriminability tests (a measure of how well representations code phonemic contrasts in the target language: lower is better) are much poorer when they do not control for the phonological context (e.g., comparing the centre phone of the word cat /kæt/ with the centre phone of the word dog /dɔɡ/ ), indicated in orange in the graph, versus when the context is controlled (e.g., comparing the centre phone of cat versus cot /kɔt/), as indicated in purple. The error rate increases by a factor of roughly 400% in some cases! This is a much greater penalty than is seen for within- versus across-speaker (triangle versus circle) or for the clean speech versus other subsets of LibriSpeech (solid versus dotted). This suggests that context-independence of the learned units is still relatively poor.
Many other issues of invariance and robustness surely remain in pre-trained acoustic models, including many (probably most) that have not even been identified yet. Progress on issues of invariance and robustness could unlock new levels of performance on higher-level tasks such as word segmentation, named entity recognition, and language modelling, where using the discretized “units” discovered by pre-trained acoustic models still lag behind state-of-the-art text-based models. Importantly, progress on talker and accent robustness would contribute to the serious fairness problem that current ASR models have (including those using pre-trained acoustic models as features) whereby lower socioeconomic status is highly correlated with higher word error rate.
Invariant and Robust Pretrained Acoustic Models 2023
The 2023 Interspeech Special Session on Invariant and Robust Pretrained Acoustic Models (IRPAM) aims to address both the evaluation problem and the problem of invariance in pretrained acoustic models.
Preliminary Schedule Wednesday, August 23rd at INTERSPEECH 2023, Dublin
All paper presentations will be oral. Presenters will have 13 minutes for the oral presentation including 3 minutes for short questions (10+3)
| Time | |
|---|---|
| 10:00 | Introduction and discussion |
| Oral presentations: Evaluation and analysis track | |
| 10:12-10:25 | ProsAudit: A prosodic benchmark for self-supervised speech models (De Seyssel et al.) |
| 10:26-10:39 | Self-supervised Predictive Coding Models Encode Speaker and Phonetic Information in Orthogonal Subspaces (Liu et al.) |
| 10:40-10:53 | Evaluating context-invariance in unsupervised speech representations (Hallap et al.) |
| Oral presentations: Model track | |
| 10:54-11:07 | CoBERT: Self-Supervised Speech Representation Learning Through Code Representation Learning (Meng et al.) |
| 11:08-11:08 | Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering (Chang et al.) |
| 11:22-11:35 | Self-Supervised Acoustic Word Embedding Learning via Correspondence Transformer Encoder (Lin et al.) |
| 11:36-12:00 | Guided panel discussion with paper authors |
The workshop will focus on two types of research:
- The evaluation track will accept proposed systematic evaluation measures, test sets, or benchmarks for pre-trained acoustic models, including but not limited to
- context-invariance
- talker-invariance
- accent-invariance
- robustness to noise and distortions.
In the interest of in-depth validation of the proposed evaluations in the limited Interspeech page limit, such papers should not propose substantive new models.
- The model track will propose new models or techniques and demonstrate empirically that they improve the invariance or robustness properties of pre-trained speech representations, evaluating using existing approaches or variants on existing benchmarks/measures. This could also include techniques for disentanglement in pre-trained acoustic models. Models submitted to this track must not be aimed at proposing new evaluation measures, and must rely primarily on standard, existing evaluations for their argumentation. Suggested evaluations for the model track include, but are not limited to:
- The ZeroSpeech Task 1 (acoustic) evaluations, focusing on within versus across-speaker measures as well as the brand new within versus across-context measures of context invariance illustrated above
- Measuring speaker- and/or accent- invariance via a decrease in performance on the SUPERB, Benchmark SID (speaker ID) task, and/or accent ID on the L2-ARCTIC corpus, following the example of this recent paper
- Evaluating noise/signal distortion robustness by applying the unit edit distance (UED) score and distortions proposed in this recent paper
Or other reproducible evaluations that can be found in the existing literature.
Organizers
- Ewan Dunbar, University of Toronto
- Emmanuel Dupoux, École des Hautes Études en Sciences Sociales / École Normale Supérieure / Meta
- Hung-yi Lee, National Taiwan University
- Abdelrahman Mohamed, Rembrand
Call for papers
Submissions for IRPAM will follow the same schedule and procedure as the main Interspeech 2023 conference, which will be held in-person in Dublin. More details to come.
Important Dates
Paper submission deadline: March 1st, 2023, 23:59, Anywhere on Earth.Paper update deadline: March 8th, 2023, 23:59, Anywhere on Earth.Author notification: May 17th, 2023- Session to be held Wednesday, August 23rd 10AM-12PM, local time, during Interspeech, August 20th to 24th, Dublin, Ireland
Contact
If you have any questions, please contact us at irpam2023@gmail.com.